
My first experience with Gleam Language
Over the past few months, I saw a growing amount of posts on X about the Gleam language (probably the X algorithm doing its thing), and decided to give it a try. I was not disappointed, with few exceptions.
Disclaimer 1: This post shares my personal experience with the language, and it is not a comprehensive review of the language. It’s not sponsored by anyone, and I’m not affiliated with the Gleam team.
Disclaimer 2: I had little prior experience with Erlang VM or functional programming in general.
Getting Started
The first thing I did was to go through the official Gleam Language Tour which was a pleasure. After an hour I familiarized myself with the syntax and the basic concepts of the language. I remember that’s how I started with Go as well, and I believe that every language must have an interactive tour like this.
|
|
The next thing I did was to install the language on my machine. I was surprised by how easy it was to install the language and the tooling on macos.
|
|
You may also need rebar3, though I didn’t need it for my project.
|
|
So far so good!
Guinea Pig Project
I prefer learning by doing, therefore I decided to build a small project with Gleam. I wanted to build a simple daemon application that monitors multiple websites concurrently from Yaml configuration and stores the results in a SQLite database.
The configuration looks similar to this:
|
|
I chose this project as I could learn about the following aspects:
- Concurrency
- HTTP calls
- Gleam packages
- Data types
- Error handling
- Yaml parsing
- Testing
Creating a new project:
|
|
This command creates a folder with a predefined structure. The boilerplate code is minimal, and I was able to start coding right away. Basically I focused on src/websites_checker.gleam and test/websites_checker_test.gleam files.
Dependencies and Imports
This part is nice as well, easy to install dependencies and import them in the code. My project needed the following dependencies:
|
|
Now, I wished I could use fewer external dependencies, but I couldn’t find how to do some things using stdlib only. For example reading file, parsing Yaml, working with time.
Dependencies are locked in gleam.toml and can be downloaded later in your CI/CD by running:
|
|
You can find a lot of dependencies in awesome-gleam repository, but many of them are very new and I would not consider them production-ready.
Parsing Yaml
Here is where I struggled the most. Maybe because I’m so used to Go’s way of parsing Yaml or JSON into a pre-defined struct. The code for parsing my configuration into a custom type is not that pretty and very verbose for multiple reasons:
- case expressions are making the code verbose and highly indented, however they provide a nice way to handle errors. And I like when errors are treated as values.
- Probably there needs to be a better package to parse Yaml in Gleam, but I couldn’t find one and used glaml which I wouldn’t call production-friendly (has 2 start on Github only?).
- There is no mutation in Gleam, so we have to use higher-level functions like
list.mapa lot.
|
|
You can see the full config.gleam file here, please reach out to me if you know how to make it shorter.
SQLite
Working with SQLite was a breeze. I used sqlight package and it does the job well. Maybe exec() function needs to accept parameters, because I had to use query() for that and had to initialize a decoder which I don’t actually need as I don’t return any data from the database, just insert it.
|
|
Concurrency and Glueing Everything Together
At this point I wrote a config parser, database layer and HTTP crawler. It was time to glue everything together and run the main loop. I wanted to create a concurrent process for each website and crawl them with a specified interval.
The concurrency is great in Gleam, I guess it inherited it from Erlang. I used gleam/erlang package to create a linked process.
|
|
You may ask why to use recursion here? There are no loops in Gleam! I think I could live with that as long as it promises immutability and no side effects.
Running in different runtimes
I used gleam run to run the project locally in Erlang VM, that worked pretty well. But I also want to explore later how to compile it to JavaScript and run it in the browser.
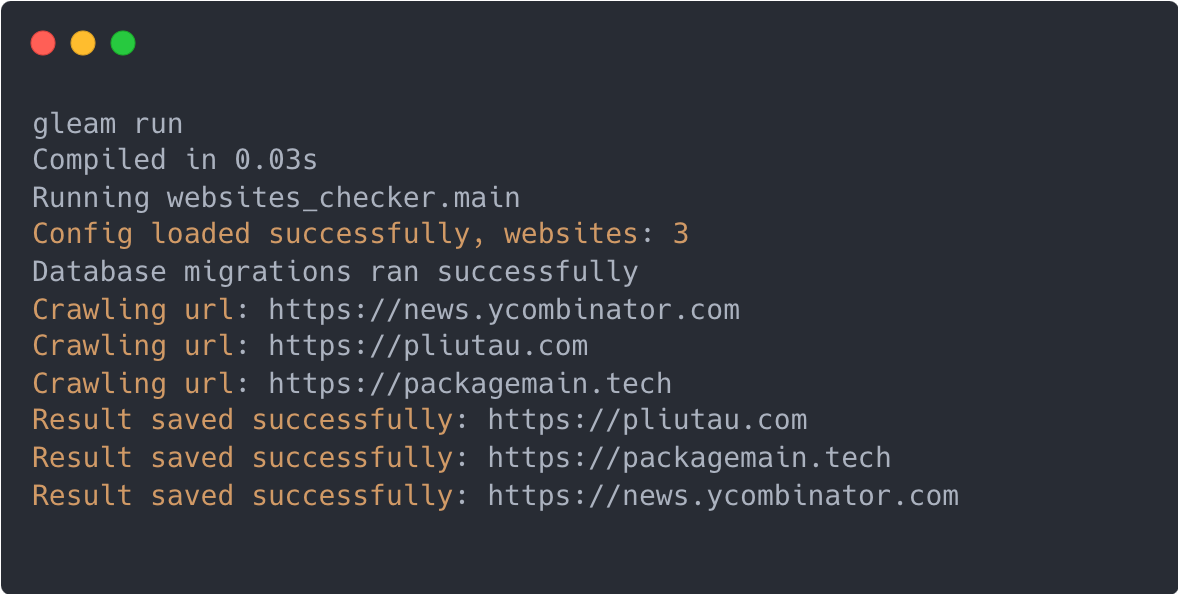
Testing
I added a simple Unit Test for my parser and it was easy to write. Then I used gleam test to run the tests.
|
|
I wanted to name the file differently but I couldn’t. Does that mean I can’t have multiple test files in Gleam?
IDE Support
I am using Zed and it just asked me to integrate the Gleam Language Server and it worked well.
Conclusion
I enjoyed writing this project in Gleam. My favorite parts were:
- Immutability and no side effects
- Pipelines, for example
first.url |> should.equal("https://packagemain.tech") Result(value, error)type for error handling- Concurrency
Learning Gleam has given me a lot of ideas and I’m looking forward to writing more projects in it.
You can see the full code in the websites_checker repository and please reach out to me if you have any suggestions for it.