Centrally Collecting Events from Go Microservices
In the beginning at Solsten our engineering team focused on building products, tools, services but we never had the time to measure what was going on in our platform (it was an early-stage startup). Even though we had a feeling of what was right or not thanks to our customers, the pain grew too strong and forced our department to allocate time in order to measure things.
After gathering some of the needs for these event metrics, it was clear to us that complex events and interactions couldn’t be tracked via our existing software logs and shouldn’t. As our team is still quite small, we were not keen to manage something like ELK stack & co.
Therefore, we opted for a more concise and homemade solution: logeater, well we should probably have called it eventeater.
Database
One consideration while choosing the database that would store our events data, was that we wanted to keep a full history of past events on top of simply having them stored for debugging purposes. We also had in mind other teams like QA, Data Science, or Data Engineering who will probably ask to have a look at these data in the future. As of now, we use it for both debugging and understanding how our platform is used so we can take better core business decisions.
Since our Data Engineering and Data Science team are using BigQuery on a daily basis, there was no need to use yet another database. It would scale for us and since it is internal metrics we don’t need real-time.
We went for clustered tables, you can see the difference between partitioned and clustered tables here. We decided to use date (day of insertion) as cluster column #cluster_key.

Schema
The raw event itself is quite simple:
|
|
More specific columns are also added. However, they are optional and sometimes not required as not all our verticals require them.
Namespaces
Events are more or less granular, to make sure we keep an extensible type convention we decided to go for namespaces. For instance, as of now, the cart event is only on 2 levels cart.add but we could extend that in the future by adding let’s say cart.add.from_mobile or cart.add.from_website if we wanted to. The rules here are to keep it clean and concise and that it makes sense immediately what the event is capturing.
Extended event tables
Some events require us to store more than just the generic data. To do so, developers have to define what is important to capture and translate this into another table inside the same dataset.
Since our event types are namespaced, they are implicitly grouped. The first level of the namespace (in our previous example cart) is automatically used as the extended table name.
Then, if all your extended tables have at least an event_id column, you can easily make a join whenever you are looking for specific events.
For instance:
|
|
Communication
Then comes the question of how does this service will communicate with others. Since there are no reasons for logeater to be accessible publicly and because we have a Service Oriented Architecture so far we opted for gRPC. It enforces an interface (or schema).
Since our team is growing and this kind of gRPC service will be used by mostly all other services we love the idea that there is a strict schema and contract (proto files) to respect in order to use logeater. It’s obviously less prone to changes, however that’s definitely for the best to avoid constant change in API.
The proto event file was thought in order to avoid changes, we accept all the fields from our event table mentioned above and an additional “details” field.
That details field is the “dynamic” component of the event message, it will contain a JSON serialized object that corresponds somewhat to the extended table data we will ingest.
We do not automatically unmarshall and ingest it. Even though it means more work every time we define a new event type, we decided that an explicit conversion should be required. That way we can accept complex business structs and then convert them into a more refined and Bigquery compliant schema.
For instance, it happens that some fields are skipped, status could be cast from integer to their readable string’s counterparts.
|
|
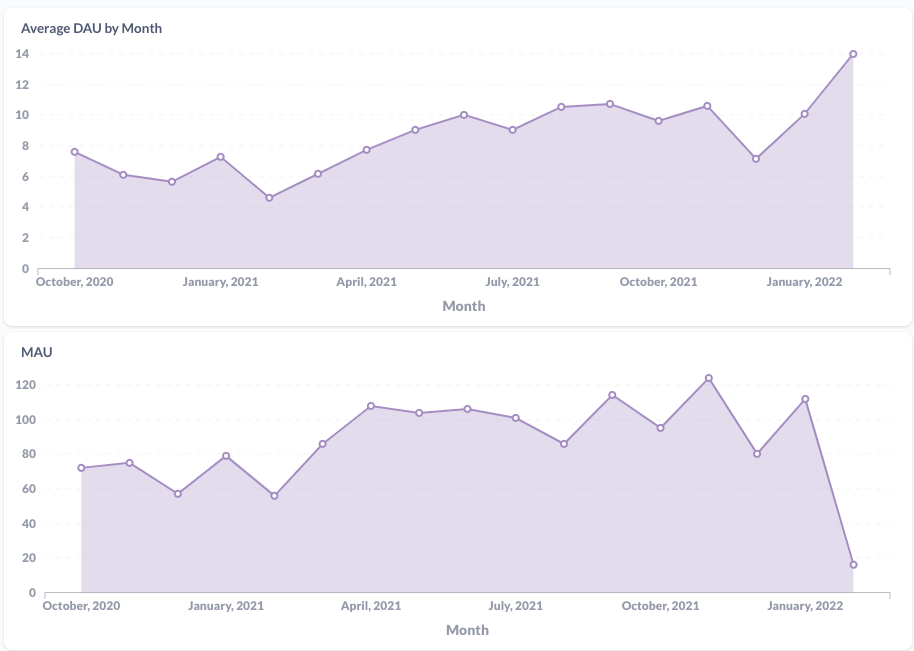
Visualization
Now that we have a huge event table that is clustered by day, events that are ready to be joined to their extended tables to extract detailed information and a gRPC service to accept and ingest that stream of data.
Only one thing remained, visualization. As our Data Engineering team started to use Metabase, we gave it a try and after 10 minutes of trial and error, we got our first dashboard containing our Most Active Users, Most Active Companies, Average Daily Active Users per month etc..